最近迫切需要巩固一下 java 基础知识,先把关于集合的整理一下,这篇文章主要介绍 List 接口以及它的实现类。
集合类框架主要接口及特点
| 接口 | 描述 |
|---|---|
| Collection | 是存放一组单值的最大接口,所有的单值是指集合中的每个元素都是一个对象。一般很少直接使用此接口直接操作。 |
| List | 是 Collection 接口的子接口,也是最常用的接口。此接口对 Collection 接口进行了大量的扩充,里面的内容是允许重复的。 |
| Set | 是 Collection 接口的子接口,没有对 Collection 接口进行扩充,里面不允许存放重复内容。 |
| Map | 是存放一对值的最大接口,即接口中的每个元素都是一对,以 key -> value 的形式保存。 |
| Iterator | 集合的输出接口,用于输出集合中的内容,只能进行从前到后的单向输出。 |
| ListIterator | 是 Iterator 的子接口,可以进行双向输出。 |
| Enumeration | 是最早的输出接口,用于输出指定集合中的内容。 |
| SortedSet | 单值的排序接口,实现此接口的集合类,里面的内容可以使用比较器排序。 |
| SortedMap | 存放一对值的排序接口,实现此接口的集合类,里面的内容按照 key 排序,使用比较器排序。 |
| Queue | 队列接口,此接口的子类可以实现队列操作。 |
| Map.Entry | Map 的内部接口,每个 Map.Entry 对象都保存着一对 key -> value 的内容,每个 Map 接口中都保存着多个 Map.Entry 接口实例。 |
部分接口的继承关系如下图所示
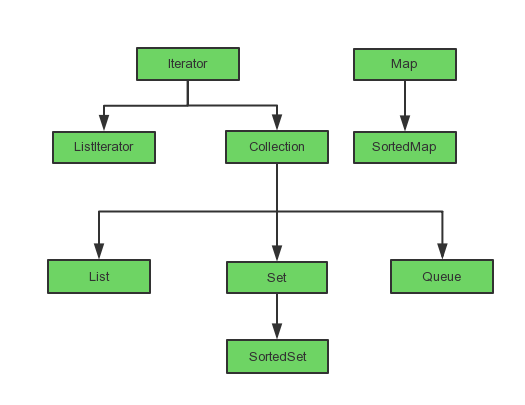
在一般的开发中,往往很少直接使用 Collection 接口进行开发,基本上都是使用其子接口。
List
List 接口继承自 Collection ,它可以定义一个允许重复的有序集合,从 List 接口中的方法来看,List 接口主要是增加了面向位置的操作,允许在指定位置上操作元素,同时增加了一个能够双向遍历线性表的新列表迭代器 ListIterator 。AbstractList 类提供了 List 接口的部分实现,AbstractSequentialList 继承自 AbstractList ,主要是提供对链表的支持。
List 接口 的常见子类:ArrayList, LinkedList, Vector
ArrayList
ArrayList 实现了可变大小的数组,允许所有元素重复,包括null。
ArrayList 遍历方式
for、foreach、Iterator
public static void demo() {
List<Integer> list = new ArrayList<>();
for (int i = 0; i < 1000000; i++) {
list.add(1);
}
long start = System.currentTimeMillis();
long sum1 = 0;
for (int i : list) {
sum1 += i;
}
long fori = System.currentTimeMillis();
System.out.println("foreach" + "-" + (fori - start) + "毫秒");
long sum2 = 0;
for (int i = 0; i < list.size(); i++) {
sum2 += list.get(i);
}
long foreach = System.currentTimeMillis();
System.out.println("fori" + "-" + (foreach - fori) + "毫秒");
Iterator<Integer> iterator = list.iterator();
long sum3 = 0;
while (iterator.hasNext()){
sum3 += iterator.next();
}
System.out.println("iterator" + "-" + (System.currentTimeMillis() - foreach) + "毫秒");
}
三种遍历方式所花费的时间分别为:
07-26 11:28:45.635 10563-10563/? I/System.out: foreach-15毫秒
07-26 11:28:45.644 10563-10563/? I/System.out: fori-9毫秒
07-26 11:28:45.660 10563-10563/? I/System.out: iterator-16毫秒
平常我们在开发中需要遍历的地方一般会选择 foreach,但 foreach 和 iterator 在 ArrayList 的遍历上却不尽人意,而 fori 的效率最高。Java 中 foreach 的实现就是通过 iterator 实现的。而 iterator 提供一种方法遍历容器的各个元素,同时又无需暴露该对象的实现细节,也就是说需要先创建一个迭代器容器,然后屏蔽内部遍历细节,对外提供 hasNext、next 方法,因为 ArrayList 实现了 RandomAccess 接口,这表明 ArrayList 是一个可以随时存取的列表,标志着这个 List 的元素之间没有关联,两个相邻的元素之间没有相互的依赖关系和索引关系,可以快速的随机访问,可视为使用 iterator 就需要强制建立一种相互“知晓”的一种关系,比如上一个元素可以判断是否有下一个元素,以及下一个元素是什么,这就是通过foreach遍历耗时的原因。
ArrayList 空间
private void grow(int minCapacity) {
// overflow-conscious code
int oldCapacity = elementData.length;
int newCapacity = oldCapacity + (oldCapacity >> 1);
if (newCapacity - minCapacity < 0)
newCapacity = minCapacity;
if (newCapacity - MAX_ARRAY_SIZE > 0)
newCapacity = hugeCapacity(minCapacity);
// minCapacity is usually close to size, so this is a win:
elementData = Arrays.copyOf(elementData, newCapacity);
}
如上代码所示,ArrayList 内部的扩容策略是当其所存储的元素数量超过它已有的大小时,新的容量等于旧的容量和旧的容量向右移1位之和,差不多就是新的容量是旧的容量的1.5倍,就是说它就会以1.5倍的容量进行扩容,也就是假如当前 ArrayList 的容量为10000,那么它在需要再存储一个元素时,即第10001个元素,由于容量不够而进行一次扩容,而ArrayList扩容后的容量则变为了15000,而多出了一个元素就多了5000个元素的空间,这太浪费内存资源了,而且扩容还会导致整个数组进行一次内存复制。
ArrayList 集合默认大小为10,因此合理的设置 ArrayList 的容量可避免集合进行扩容。所以:
- 预知容量的情况下构造ArrayList时尽量指定初始大小
- 当需要插入大量元素时,在插入前可以调用 ensureCapacity 方法来增加 ArrayList 的容量以提高插入效率
ArrayList 同步性
ArrayList 是非同步的(unsynchronized),因此 ArrayList 中的对象并不是线程安全的。因为同步的要求会影响执行的效率,所以如果你不需要线程安全的集合那么使用 ArrayList 是一个不错的选择,这样可以避免由于同步带来的不必要的性能开销。
LinkedList
LinkedList 基于链表实现,它提供额外的 get,remove,add 方法在 LinkedList 的首部或尾部。这些操作使 LinkedList 可被用作堆栈(stack),队列(queue)或双向队列(deque)。
LinkedList 遍历方式
for、foreach、Iterator
public static void demo() {
List<Integer> list = new LinkedList<>();
for (int i = 0; i < 100000; i++) {
list.add(1);
}
long start = System.currentTimeMillis();
long sum1 = 0;
for (int i : list) {
sum1 += i;
}
long fori = System.currentTimeMillis();
System.out.println("foreach" + "-" + (fori - start) + "毫秒");
long sum2 = 0;
for (int i = 0; i < list.size(); i++) {
sum2 += list.get(i);
}
long foreach = System.currentTimeMillis();
System.out.println("fori" + "-" + (foreach - fori) + "毫秒");
Iterator<Integer> iterator = list.iterator();
long sum3 = 0;
while (iterator.hasNext()){
sum3 += iterator.next();
}
System.out.println("iterator" + "-" + (System.currentTimeMillis() - foreach) + "毫秒");
}
三种遍历方式所花费的时间分别为:
07-27 03:57:56.147 5802-5802/com.smile.kotlindemo I/System.out: foreach-2毫秒
07-27 03:58:00.791 5802-5802/com.smile.kotlindemo I/System.out: fori-4644毫秒
07-27 03:58:00.793 5802-5802/com.smile.kotlindemo I/System.out: iterator-2毫秒
从运行结果可以看出,在 LinkedList 的遍历上,for 和 foreach 的差距不是一星半点。LinkedList 类虽然也是一个列表,但它实现了双向链表,每个数据节点 node 都有三个数据项:前一个节点的引用、本节点元素、下一个节点的引用,也就是说 LinkedList 的两个元素之间是有关联的,我知道你的存在,你知道我的存在,所以对 LinkedList 等以链表实现的集合遍历时使用foreach或者iterator性能最佳。
LinkedList 空间
private static class Node<E> {
E item;
Node<E> next;
Node<E> prev;
Node(Node<E> prev, E element, Node<E> next) {
this.item = element;
this.next = next;
this.prev = prev;
}
}
在 LinkedList 中有一个私有的内部类,定义如上代码所示,每个 Node 对象对应列表中的一个元素,同时还有在 LinkedList 中它的上一个元素和下一个元素。一个有1000个元素的 LinkedList 对象将有1000个链接在一起的 Node 对象,每个对象都对应于列表中的一个元素。这样的话,在一个 LinkedList 结构中将有一个很大的空间开销,因为它要存储这1000个 Node 对象的相关信息。
LinkedList 同步性
LinkedList 是非同步的(unsynchronized),因此 LinkedList 中的对象并不是线程安全的,如果多个线程同时访问一个LinkedList ,则必须自己实现访问同步。
Vector
Vector 和 ArrayList 非常类似。
Vector 遍历方式
for、foreach、Iterator
同 ArrayList
Vector 空间
private void grow(int minCapacity) {
// overflow-conscious code
int oldCapacity = elementData.length;
int newCapacity = oldCapacity + ((capacityIncrement > 0) ?
capacityIncrement : oldCapacity);
if (newCapacity - minCapacity < 0)
newCapacity = minCapacity;
if (newCapacity - MAX_ARRAY_SIZE > 0)
newCapacity = hugeCapacity(minCapacity);
elementData = Arrays.copyOf(elementData, newCapacity);
}
如上代码所示,Vector 内部的扩容策略是当其所存储的元素数量超过它已有的大小时,是新的容量是旧的容量的2倍,就是说它就会以2倍的容量进行扩容,也就是假如当前 Vector 的容量为10000,那么它在需要再存储一个元素时,即第10001个元素,由于容量不够而进行一次扩容,而Vector 扩容后的容量则变为了20000,而多出了一个元素就多了10000个元素的空间,这太浪费内存资源了,而且扩容还会导致整个数组进行一次内存复制。
Vector 集合默认大小也为10,因此合理的设置 Vector 的容量可避免集合进行扩容。所以:
- 预知容量的情况下构造Vector 时尽量指定初始大小
- 当需要插入大量元素时,在插入前可以调用 ensureCapacity 方法来增加 Vector 的容量以提高插入效率
Vector 同步性
Vector 是同步的(synchronized),因此 Vector 是线程安全的,当一个 Iterator 被创建而且正在被使用,另一个线程改变了 Vector 的状态(例如,添加或删除了一些元素),这时调用 Iterator 的方法时将抛出 ConcurrentModificationException,因此必须捕获该异常。所以大多数情况下不使用Vector,因为线程安全需要更大的系统开销。
总结
- ArrayList 是最常用的 List 实现类,内部是通过数组实现的,它允许对元素进行快速随机访问。数组的缺点是每个元素之间不能有间隔,当数组大小不满足时需要增加存储能力,就要将已经有数组的数据复制到新的存储空间中。当从 ArrayList 的中间位置插入或者删除元素时,需要对数组进行复制、移动、代价比较高。因此,它适合随机查找和遍历,不适合插入和删除。
- Vector与ArrayList一样,也是通过数组实现的,不同的是它支持线程的同步,即某一时刻只有一个线程能够写 Vector,避免多线程同时写而引起的不一致性,但实现同步需要很高的花费,因此,访问它比访问 ArrayList 慢。
- LinkedList 是用链表结构存储数据的,很适合数据的动态插入和删除,随机访问和遍历速度比较慢。另外,他还提供了 List 接口中没有定义的方法,专门用于操作表头和表尾元素,可以当作堆栈、队列和双向队列使用。
所以,开发中使用哪个要根据情况来决定,不同的使用方法,将使我们在开发过程中事半功倍。
